À medida que os cenários de uso de IoT se expandem, as organizações concluirão que a infraestrutura necessária não se assemelha a uma infraestrutura tradicional
|
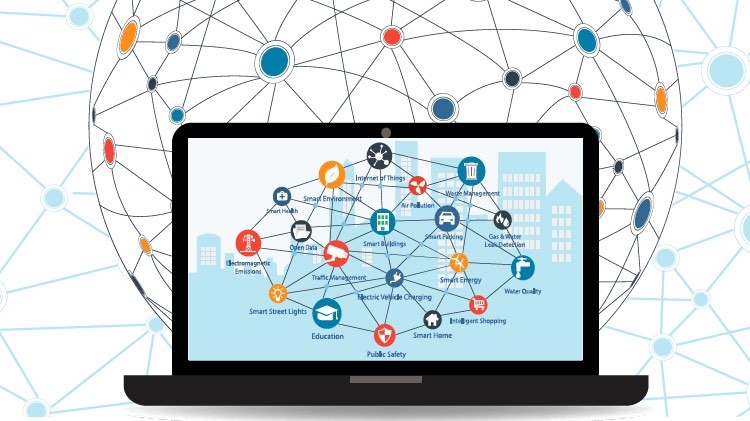
Primeiro, surgiram os telefones inteligentes. A cada nova iteração, mais sensores: acelerómetros, giroscópios, localização. Depois, todos os instrumentos que a eles se ligam, sejam relógios ou balanças. Subitamente, parece que de forma contínua surgem novas categorias de dispositivos, seja para utilização pessoal, seja empresarial (embora as fronteiras entre ambas as áreas de utilização estejam cada vez mais esbatidas), dotados de sensores, com razoável capacidade de processamento e várias opções de conetividade. Todos estes dispositivos, de utilização estática ou dinâmica, com sensores e capacidades de ligação a uma rede de comunicação, habitualmente sem fios, se integram na categoria de Internet das coisas (IoT). A infraestrutura hiperdistribuídaÀ medida que os cenários de uso de IoT se expandem e diversificam, cada vez mais organizações concluirão que a infraestrutura necessária para a suportar não se assemelha ou comporta como uma infraestrutura tradicional. À medida que as expetativas dos clientes crescem, os requisitos de desempenho não tolerarão as latências de acesso a um recurso remoto. As camadas aplicacionais dividir-se-ão entre o edge (limiar) e os centros de dados mais convencionais. Pelo meio, surgirão novas categorias de dispositivos. A nova arquitetura que integra estes dispositivos de forma coerente diz-se hiperdistribuída (uma designação popularizada pela Forrester), por apresentar um grau de dispersão espacial muito superior ao das atuais arquiteturas distribuídas. Fog ComputingA introdução da IoT traz milhões de dispositivos para a internet e a maioria destes dispositivos são de recursos limitados. Para superar os desafios colocados pelas capacidades reduzidas e satisfazer as exigências do domínio aplicacional, torna-se evidente a procura por uma camada de computação intermediária. Assim surge o conceito de fog computing, que é uma camada de computação mais próxima da camada de perceção, onde residem os sensores e atuadores, proporcionando os serviços de computação, rede e armazenamento. Em contraste com a camada de cloud, a camada de fog está mais perto da camada de perceção e esta proximidade proporciona uma gama de vantagens sobre a cloud. Uma dessas é o seu conhecimento sobre localização. Tal conhecimento advém da distribuição geográfica em larga escala dos dispositivos que compõem a camada fog. Cada gateway de entrada na camada de fog gere um subconjunto de nós na camada de perceção ou de sensores. Estes dispositivos de recursos limitados estão localizados próximo uns dos outros e o gateway que os gere pode facilmente localizar cada dispositivo. O conhecimento de localização por parte da camada de fog pode ser usado para endereçar requisitos funcionais e não funcionais múltiplos de aplicações IoT, como a segurança e a mobilidade. Outra caraterística relacionada de muito perto com a camada fog é a sua distribuição em larga escala, o que contrasta com a camada de cloud, que é centralizada ou, melhor dizendo, embora esteja distribuída geograficamente, não o está à escala do nível fog. Fornecedores de serviços de cloud como a Amazon ou a Microsoft têm múltiplos data centers em regiões diferentes. Mas a distribuição geográfica na camada de fog é diferente devido à pequena distância de separação entre os gateways e as suas implementações alargadas. Os benefícios combinados do conhecimento da localização e a distribuição geográfica de larga escala suportam os requisitos de mobilidade dos dispositivos, ou coisas, ao nível da perceção. A proximidade entre a camada de fog e os nós proporciona um modo de interação em tempo real com os sensores e atuadores na camada de perceção. A distribuição geográfica da camada de fog e, subsequentemente, a baixa latência da comunicação, estão entre as caraterísticas críticas da camada de fog. Alguns domínios aplicacionais de IoT, como o dos cuidados de saúde ou as futuras aplicações dos automóveis de condução autónoma, estão muito dependentes desta caraterística. A difusão das tecnologias de informação segue, com frequência, da dicotomia centralização/distribuição. Depois do impulso nos últimos anos para a adoção das plataformas de cloud, neste momento o pêndulo está a virar-se para o limite, o edge. O edge e a cloud não competem: complementam- se. Será crucial perceber, tão cedo quanto possível, que os dados gerados pelo fog não viajarão até ao centro da cloud para serem processados. Não haverá tempo de espera, nem largura de banda para tal. O modelo futuro será híbrido: cloud e edge. Mais uma vez, estamos a assistir a uma alteração de paradigma. A hiperdistribuição obrigará a repensar protocolos, normas, infraestruturas, papéis. Esta é uma indústria onde, parafraseando a canção, e tal como a cidade de Nova Iorque, nunca se dorme. |
Receba todas as novidades na sua caixa de correio!



